Pelee 리뷰
Pelee - A Real-Time Object Detection System on Mobile Devices 리뷰
가벼워도 성능 좋고 스피드도 빠르다! 3마리 토끼를 잡은 detector
SSD 가 나오고도 벌써 3년, 수많은 Convolutional Neural Network 기반의 detector 들이 등장하였다.
FPN, RetinaNet, YoloV3 등 성능적인 부분을 개선한 논문도 있고 속도적인 부분을 개선한 논문도 많다.
모두 훌륭한 논문이지만, 오늘 볼 것은 다른 쪽으로 노력한 친구들이다.
SSD로 돌아가서, 해당 모델이 빠른 것인 사실이지만, 그것은 언제나 연구환경 에서다.
59FPS의 놀라운 성능은 TITAN X, Intel Xeon E5-2667v3@3.20GHz에서 발생한다.
SSD를 연구실 환경에서 열심히 돌려봤는데 정말 아무리 잘 나와야 45FPS 정도였다.
만약 이 모델을 그대로 핸드폰에서 돌린다면 답답한 속도와 함께 핸드폰은 따뜻한 손난로로 변할 것이다.
이러한 제한된 메모리와 연산력에서 빠르고 정확한 detector 가 오늘 볼 논문 Pelee의 목표이다.
이 분야의 대표주자로 MobileNet, MobileNetV2, ShuffleNet 가 있다.
각각이 가지고 있는 특징들은 조금씩 다르지만, 한 가지 공통점으로 Depthwise Seperable Convolution(Dw convolution) 을 사용한다. 이 분야의 선구자인 MobileNet 을 시작으로 연산량 줄이기위해 정석적으로 사용되는 방식이었다.
기존은 3 x 3 x M x N filter 를 썼다면 dw convolution 에서는 3 x 3 x 1 x M 과 1 x 1 x M x N 을 쓰는 것이다.
성능은 비슷하지만 연산량은 크게 준다! ((3 x 3 x M x N) x w x h vs (3 x 3 x M + M x N) x w x h)
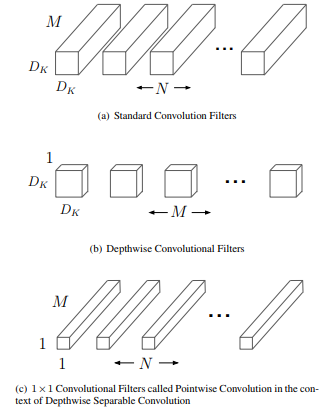
Pelee 는 이에 당돌하게 맞서며 Conventional Convolution 으로 충분하다고 나온 논문이다.
Abstract 와 Introduction 에 계속 현재 딥러닝 프레임워크로 효율적으로 구현하기 어렵다 를 강조하는 것을 보면 아마 위 논문들을 구현하다가 그 복잡함에 단단히 화가 난 것 같다.
차근차근 그들의 논문을 살펴보며 Conventional Convolution만으로 어떻게 극복하였는지 살펴보자.
Depthwise Seperable Convolution 게섯거라, 토종 Convolution 나가신다!
CNN을 제한된 메모리와 계산량으로 좋은 성능을 내려던 시도는 전에도 많이 있었으며, 아까도 말한 MobileNet 과 ShuffleNet 이 그 선두주자라 할 수 있겠다.
다만 이 두 개의 경우 dw convolution 에 크게 의존하고 있으며, 현재 딥러닝 라이브러리에서 구현의 효율도 떨어진다며 다른 방식을 제시한다.
Classification 과 Detection 양쪽 모두에서 효율적인 구조를 만들기 위해 새로 설계한 CNN architecture, PeleeNet 과 Pelee 이다.
Mobile Device 를 위한 DenseNet 기반의 PeleeNet
PeleeNet 은 DenseNet-41을 변형시켜 만든 네트워크로 MobileNet 에 비해서 66% 밖에 안 되는 모델 크기를 가지면서 성능도 1.5% 높고 속도도 아주 빠르다고 한다. (NVIDIA TX2에서 1초에 240장의 이미지 분류!)
그렇다면 어떤 방식을 이용해 dw convolution 없이도 좋은 성능을 보일 수 있었을까?
-
원래의 Dense layer 대신 Two-way Dense layer 를 사용한다.
원래 DenseNet 에 사용되는 Dense layer 에는 1 x 1 과 3 x 3, 두 개의 convolution 결과를 원본과 concatenate 하여 사용된다.
여기에 3 x 3 convolution 을 두 번 시행한 결과를 같이 이용한다면? dense layer 를 두 개 쌓은 것과 비슷한 receptive field 를 한 layer 로 얻을 수 있을 것이다.
자세히 알고 싶다면 이 방식을 가장 먼저 사용했던 GoogLeNet 을 참조해보자
원래는 4k 와 k channel convolution 의 1-way 를 2k , k/2 channel convolution 의 2-way 로 변경했기에 연산량도 크게 다르지 않다.
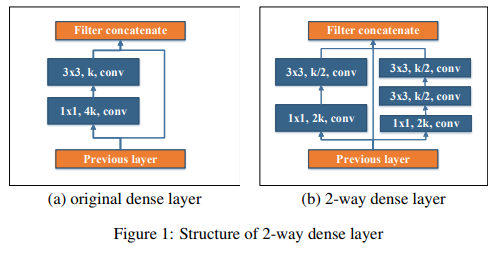
-
Stem Block 을 Dense Block 전에 둔다.
DenseNet 에서도 그렇고 Inception-v4 나 DSOD 논문을 살펴보면 Block 을 쌓기 전에, 간단한 convolution 을 통해 feature를 뽑는 단계가 있다.
이 논문들의 공통된 의견은 input 에 바로 block 을 쌓는 것보다 먼저 간단한 convolution 을 거치는 것이 훨씬 효율적이라는 것이다.
PeleeNet 의 특징이라면 다른 구조들은 단순 convolution 쌓기 구조라면, 여기서는 Inception을 사용한다는 것이다.
아무래도 다른 구조에 비해 얕은 dense block 때문에 이러한 선택을 한 것으로 보이지만, 정확한 이유는 나와있지 않았다…
후에 이에 대해서도 한번 실험해볼 계획이다.
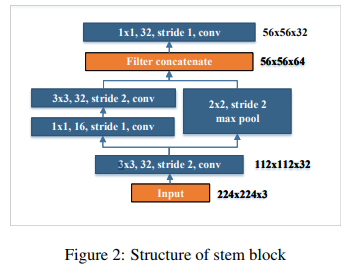
-
BottleNeck Layer 의 채널 수를 유동적으로 한다.
Bottleneck Layer 는 1 x 1 Convolution 으로 channel 수를 줄여 연산량을 줄이는 방식이다.
그런데 그 채널 수는 항상 4k (k 는 growth rate)인데, 자세히 보니 초반의 몇 layer 는 오히려 channel 수가 더 많아지는 현상이 있다는 것을 발견하였다.
(k=32의 첫 dense block 은 처음에 64로 시작하는데 bottleneck에서 128이 된다.)
이러면 오히려 연산량을 늘게되고, DenseNet 이 의도했던 방향과 맞지 않게 된다.
따라서 channel 의 수를 block 에 따라 유동적으로 바꿔, bottleneck 에서 channel이 늘어나는 불상사가 일어나지 않게 하였다.
이 과정에서 accuracy 는 조금 줄었지만, 연산량은 28.5 % 나 줄었다고 한다.
자세한 channel 수는 원본 코드에서 직접 확인하자.
-
Transition Layer 의 Compression 을 사용하지 않는다.
나름 DenseNet 의 핵심 부분이라고 할 수 있는 Transition 의 Compression 부분을 과감하게 삭제하였다.
비교했더니 성능이 떨어져서 그렇다고 한다.
네트워크가 얇아서 그런것일까? 아니면 Compression 자체가 문제가 있는것일까?
DenseNet 논문을 읽어보면 Compression만 성능 비교를 한 부분이 없고 치사하게 Bottleneck 이랑 묶어 놔서 알 수가 없긴 하다.
이 부분도 추가적으로 연구해볼만한 부분이라고 생각된다.
-
Composite Function 을 변경함
DenseNet 의 Composite function 은 BatchNorm - Relu - Conv 순서로 이루어진다. (pre-activation)
하지만 PeleeNet 은 Conv - BatchNorm - Relu 순으로 이루어진다. (post-activation)
무슨 차이가 있을까 싶지만, Conv와 BatchNorm 이 이어져있다는 점이 중요하다.
둘이 이어짐으로 Conv와 BatchNorm 을 한 layer 로 합칠수가 있게 되며, Inference stage 에서 굉장히 빨라진다고 한다.
물론 이러한 변화가 성능에 하락을 주기 때문에,
-
네트워크를 얇고 넓게 설계
-
1 x 1 conv layer 를 마지막 dense block 뒤에 추가
등으로 해결했다고 한다.
-
PeleeNet 은 classification 알고리즘! Pelee 은 SSD 와 결합한 detection 알고리즘!
이제 PeleeNet 으로 detection 에 써볼 차례다.
가벼운 classification 네트워크에 어울리는 것은 역시 가벼운 detection 알고리즘이다.
저자들이 선택한 것은 Single Shot MultiBox Detecotr 였다.
그냥 쓰지는 않고, 몇가지 변형을 통해 사용하여 Yolov2 에 비해서 VOC 에서는 mAP 가 1.9%, 방식에 따라 다르긴 하지만 COCO 에서도 조금 더 좋은 성능을 보인다.
-
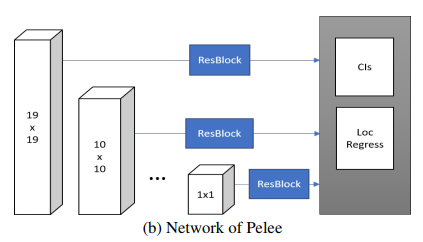
38 x 38 feature map… 안써요 어휴
SSD 는 38 x 38, 19 x 19, 10 x 10, 5 x 5, 3 x 3, 1 x 1 총 6가지의 feature map 을 선택한다.
이 부분을 잘 모르겠다면 전 post 를 확인해보면 도움이 될것이다.
가장 작은 부분 탐지를 위해 사용되는 38 x 38 의 경우 성능도 구린 주제에 전체 prediction 의 66% 나 차지한다 (5776 / 8732)
차라리 38 x 38 은 버리고 다른 방식으로 정확성을 올리는 방법을 쓰는 것이 속도 향상에 도움이 된다.
Pelee 는 이에 따라 38 x 38 을 빼고, 19 x 19 가 그 역할을 같이 하도록 구현하였다.
그래서 19 x 19 with two scales, 10 x 10, 5 x 5, 3 x 3, 1 x 1 이렇게를 최종 feature map 으로 사용하게 된다.
-
Residual Prediction Block
Residual Block 을 Prediction 을 하는 방식은 RUN 에서 제안한 방식을 가져온 것이다.
prediction 을 하기 전에 ResBlock 하나를 이용해서 해당 피쳐를 더 좋은 피쳐로 만드는 과정이다.
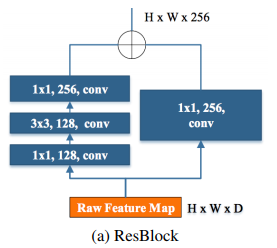
-
Small Convolutional kernel Prediction
원래는 3 x 3 convolution 으로 최종 prediction 을 한다. 하지만 위의 ResBlock 을 보면 이미 3 x 3 convolution 이 들어갔으니, 한 번 더 쓸 필요가 있을까?
저자들은 3 x 3 대신 1 x 1 로 대신하여 거의 비슷한 결과를 얻으면서도 21.5%의 계산량을 줄일 수가 있었다.
이렇게 완성된 pelee! SSD 에 비해 간결한 것이 느껴진다.
Results
개인적으로 모든 결과에 대해서 언급하는 것을 좋아하지 않기 때문에, 중요하다고 생각하는 몇 개만 이야기를 하도록 하겠다.
더 자세한 내용이 필요하다면 논문을 참고하자.
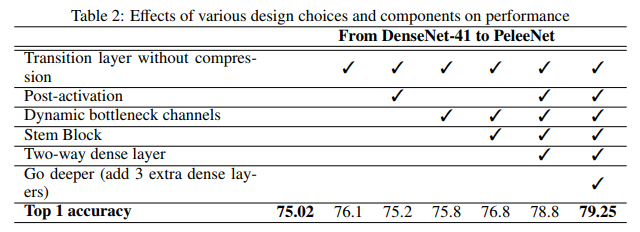
위 결과는 DenseNet-41 을 baseline으로 하여 PeleeNet 으로 변형한 기법 들을 ablation test 한 결과이다.
해당 DenseNet 은 저자가 제한된 Computation Budget 에 맞춰 channel 수 등 몇 가지를 변형한 모델이다.
dataset 은 Standford Dog dataset을 이용해서 실험하는데, 이것만 가지고는 데이터가 너무 적어서 Imagenet 에서 추가로 가져와서 150,466 장을 training set 으로, 6,000 장을 validation set 으로 사용하였다.
필자는 차례대로 아래와 같이 해석하였다.
- compression 을 제거하여 성능이 향상됨
- post-activation 을 시도했는데 성능이 하락함, 하지만 속도를 늘리기에 최적화된 방법이기에 이를 보완할 방법을 먼저 찾고 싶은 듯 하다
- 다시 pre-activation으로 돌리고, Dynamic Bottleneck channel 을 시도했더니 이 역시 성능이 살짝 떨어짐. 다만 이는 연산량이 크게 줄기 때문에 허용수치로 볼 수 있다
- Stem Block 을 적용시켰더니 76.8이라는 꽤나 높은 수치를 얻음
- 여기에 Post-Activation 을 다시 적용시키고, 2-way dense layer 를 이용하니 78.8 이라는 꽤 높은 수치를 얻음
- 마지막으로 dense layer 를 추가로 3개를 쌓았더니 최종적으로 79.25라는 수치를 얻음
마지막에 3개의 layer를 추가해도 연산량은 DenseNet-41 보다 적기 때문에 추가한 것으로 보인다.
이렇게 한 결과는 전에 말했듯이 다른 dw convolution 을 사용한 결과보다 연산량은 적으면서 좋거나 비슷한 결과를 보였다.
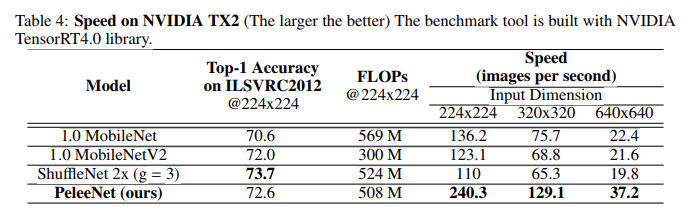
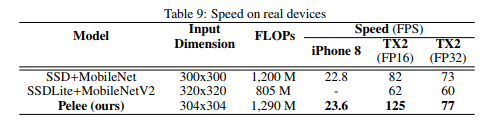 특히 속도 쪽은 더욱 부각되는데, 224 x 224 classification 의 240 images for second 라는 놀라운 속도는 다른 네트워크에 비해 2배 가까이 빠른 속도이다.
특히 속도 쪽은 더욱 부각되는데, 224 x 224 classification 의 240 images for second 라는 놀라운 속도는 다른 네트워크에 비해 2배 가까이 빠른 속도이다.
detection 부분도 똑같이 SSD 를 사용한 다른 네트워크에 비해 2배가까이 높은 속도를 보인다.
다만 FP32 가 되면 속도 차이가 많이 줄어드는데, 이는 TX2 의 FP16에서의 dw convolution 연산 문제라고 한다.
Conclusion
Pelee 는 dw convolution 을 사용하지 않고도 그에 버금가는 성능과 함께 제한된 메모리, 계산력에서도 사용할 수 있는 네트워크를 제시하였다.
Convention convolution 만으로 이러한 성능을 내었으니, 추가적인 기법을 통해 훨씬 효율적인 detector를 만들 수도 있을 것 같다.
다만 이 논문의 evaluation 부분은 아쉽게 느껴진다.
DenseNet-41 에서 layer 를 추가한 것과 accuracy 성능 비교를 하는 것이 그 부분인데, DenseNet-41 은 원래 있던 구조가 아닌 저자들이 base 삼아 만든 구조이다.
어차피 DenseNet-41 을 mobile device 에서 사용할 생각이 아니었다면, 성능 비교의 지표는 똑같이 3 dense layer 를 추가시킨 DenseNet-47 과 했으면 더 의미있을 것이라 생각한다.
또한 TX2 FP16 일 때를 제외하고, 다른 상황에서의 속도 차이를 다른 device 에서도 추가적으로 실험이 더 필요하다고 생각한다.
TX2 FP16 상황을 제외하면 속도가 비슷하기 때문에, TX2 의 문제라고 생각되기 때문이다.
Dw convolution 없이도 속도가 비슷한 것도 하나의 contribution 라고 생각하는데, 충분한 실험이 없으니 무언가를 숨기는 듯한 느낌을 받아 찜찜하다.
기회가 되면 이 부분은 직접 해봐서 확인해보려고 한다.
댓글남기기