SSD 리뷰
Single Shot MultiBox Detector 리뷰
빠르고 강력한 Detector
SSD가 등장하기 전까지 많이 사용되던 대표적인 detector는 Faster R-CNN이다.(Faster R-CNN 논문)
이 Faster R-CNN은 Detecting을 위해
- 들어온 image의 후보 영역을 열심히 뽑아서! (Region Proposal Network)
- 뽑은 부분의 특징이나 픽셀을 resampling 하고
- 그 뒤에 높은 성능의 classifier를 이용하는 것이다.
(비슷한 시기에 나온 detector들은 대부분 이 과정을 거치게 된다.)

하지만 Faster R-CNN은 전작인 R-CNN을 열심히 개선했음에도 불구하고 너무 느려서 (7 FPS with mAP 73.2% ) 실시간 영상분석에 사용할 수는 없었다.
YOLO 는 빠르긴 했지만 그만큼 성능을 포기하게 되었다.(45 FPS with mAP 63.4%)
하지만 SSD는 후보 영역 추출 과정과 resampling 과정을 제거한 방식을 이용하여 높은 정확성과 빠른 속도를 모두 얻어냈다. (59 FPS with mAP 74.3%)
(위의 모든 성능 측정은 VOC2007 test를 기반으로 한다)
이 포스트에서는 SSD가 어떻게 이런 놀라운 성능을 가질 수 있게 되었는지 공부해볼 것이다.
SSD 가 빠르고 좋은 이유는 뭐지?
SSD는 전부 새로 만든 구조가 아니다. 원래 잘 만들어졌던 feed-forward convolutional network에서 feature map을 뽑아내는 과정까지를 하나의 기본 구조로 가지고, 여러 보조적인 몇 가지 구조만을 추가한 것이다.
논문에서는 VGG-16 network에서 conv5_3까지를 잘라서 기본 구조로 사용하였다. 현재 2017년 9월 7일 기준으로 6020회의 인용이 있는 network인 만큼 feature map을 놀랍도록 잘 뽑아낸다!
사실 Faster R-CNN도 그렇고, 잘 되던 네트워크를 가져다 쓰는 건 많은 논문에서 하고 있다. 하지만 SSD가 특히 좋은 성능을 보여준 이유는 바로 Single-shot learning 과 보조 구조에 있다.
SSD의 Framework를 천천히 살펴보면서 SSD가 가지고 있는 특징을 살펴보자.
1) single-shot detector
Single-shot detector는 말 그대로 사진의 변형 없이 그 한 장으로 훈련, 검출을 하는 detector를 의미한다.
그 의미를 알기 위해 다른 deep learning detector를 먼저 살펴보자.
보편적으로 사용되고 있는 Deep-learning Detector 들은 처음 훈련시킨 크기만을 입력으로 받을 수 있다. 대표적으로 VGG-16, Alexnet에서 주로 224X224 크기의 이미지를 입력으로 받는다.
224X224 크기의 이미지를 입력으로 받아, 그 결과를 1000 labels에 대한 확률로 반환해준다. (출처: http://www.datalearner.com)
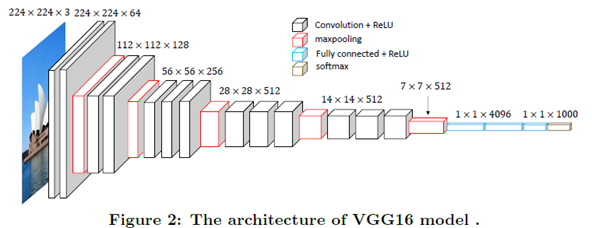
즉 원하는 사진에서 객체가 있는지 없는지 확인하기 위해서는 그림을 224X224로 자르거나 변형 알아내야 한다. 이러한 과정을 위해 Image Pyramid & Sliding Window 라던가, Region Proposal Network(Faster R-CNN)등으로 입력 이미지를 변형시켜 네트워크 집어넣게 된다.
문제는 위의 처리 과정을 통해 얻은 여러가지 sample 들을 하나씩 network에 넣어서 하나씩 검출 해야 한다는 것이다. 여러 장의 정보를 처리해야하기 때문에 그만큼 네트워크를 많이 돌게 되고, 횟수 차이에 의한 속도의 저하가 일어나게 된다.
위와 같은 이유로 Single-shot detector가 상대적으로 검출 속도가 빠른 것이다.
2) Multi-scale feature maps for detection
하지만 single-shot learning을 위해서는 큰 문제 하나를 해결해야 한다.
단! 한장의! 사진만을 가지고 여러가지 크기의 물체를 검출해야 한다.
SSD는 이러한 문제를 기본 구조 뒤에 보조 구조를 붙여 얻은 Multi-scale feature maps 을 이용해서 해결하였다.
멍멍이와 야옹이는 크기가 두 배정도 다르기에 크기가 다른 feature map들에서 찾아내게 된다. (출처: SSD 논문)
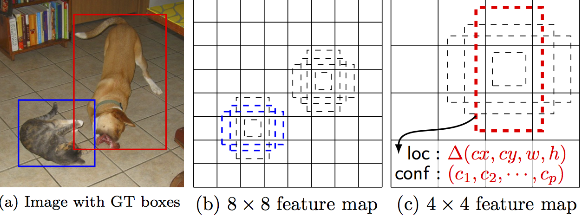
위 사진에서 멍멍이의 크기는 사진의 1/3 가량인데 반해, 고양이는 대략 1/6 정도로 둘의 크기 차이가 크다. 이를 한가지 feature map에서 구하려면 bounding box의 크기차이가 크기 때문에, box의 크기 추정부터 위치 추정까지 많은 과정이 필요할 것이다.
하지만 SSD 는 그렇지 않고, feature map을 여러 개의 크기로 만들어서, 큰 map에서는 작은 물체의 검출을, 작은 map에서는 큰 물체의 검출을 하게 만들었다. 후술하겠지만, 이러한 방식은 위치 추정 및 입력 이미지의 resampling을 없애면서도 정확도 높은 결과를 도출하게 된다.
3) Convolutional predictors for detection & Default boxes and aspect ratios
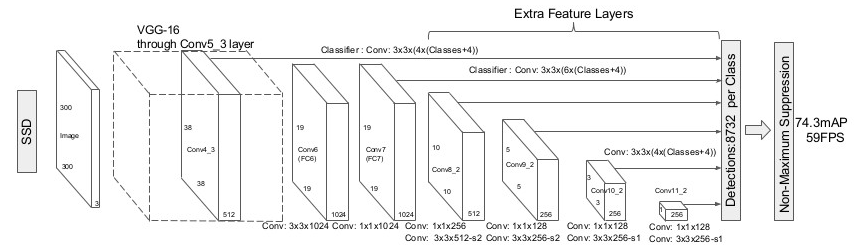
이 것이 SSD 의 architecture이다. 기본 구조나 보조 구조에서 얻은 feature map들은 각각 다른 convolutional filter에 의해 결과값을 얻게 된다.
m x n 을 p 채널을 가지고 있는 feature map은, 각 위치 마다 3 x 3 x p kernel들 을 적용할 수 있으며, 각 kernel(filter) 은 카테고리 점수나 bounding box offset 점수를 알려주게 된다.
한 가지 예를 들어보자. bounding box offset이란 각 cell(feature map 한 칸)을 기준으로 한 상대적 위치와 박스의 크기를 의미한다. 이를 위해 필요한 정보는 x, y, width, height 로 4개이다. 즉 이들을 표현하기 위해 한 cell 당 4개의 filter들로 표현할 수 있게 되는 것이다.
마찬가지로 카테고리 점수는 각 label 마다 얼마만큼의 가능성이 있는 것인지 표시하는 것이기에, 한 카테고리당 하나의 filter로 표현할 수가 있다. 만약 c개의 카테고리가 있었다면, 한 cell 당 (c + 4)개의 filter로 표현 할 수 있다는 것이다.
….만! 사실 offset에서 실제 bounding box의 크기를 말하지 않는다. 실제 박스와 예측 박스가 정확히 일치하는 것이 제일 좋겠지만, 너무나도 어렵고 비효율적이다. 그래서 aspect ratio라는 개념을 도입하였다. 이는 상자가 가질만한 비율을 몇 가지만 추려서 정답은 이 안에 있어! 라고 추정하는 것이다. (이 비율들을 가진 상자들을 default boxes라 부른다.)
이는 위 사진에 잘 표현되어 있다. 약간의 정확도를 포기하지만 빠르고 나쁘지 않은 성능을 보여준다. 그래서 만약 aspects ratio가 k개라 했을 때 실제로 한 cell 당 (c + 4) x k 개의 filter를 적용하게 된다.
논문에서는 5개의 feature map에 대해서, 전부 다른 filter들을 사용함으로 크기에 상관없이 검출할 수 있는 환경을 만들었다. 이러한 방식 덕분에 위치 추정 및 resampling 없이도 높은 정확도를 가진 detector가 완성된 것이다.
SSD 훈련하기
위에서 구조에 대해서 알아보았다. 이제 중요한 것은 어떻게 훈련을 시키는가 이다. 많은 논문에서도 종종 언급되는 문제가 훈련 방법이다. 인공신공망이라는 이름에 안 어울리게 훈련을 대충하면 결과도 대충 나온다.다행히도 대부분의 논문에는 저자들이 피땀흘려 얻어낸 훈련법이 있기 때문에, 자세히 읽어보는 것이 좋다.
SSD 를 훈련시킬 때 중요한 점은 물체 뿐만 아니라 위치가 정확하게 표시된 dataset이 필요하다는 것이다. 그렇기에 다른 detector와는 살짝 다른 방식으로 훈련을 하게 된다.
1) Matching Strategy
SSD가 예측한 박스와 실제 박스가 일치하는 지를 확인하는 것은 매우 중요한 문제이다. 이럴 때 가장 많이 사용하는 것은 jaccard overlap, 혹은 intersection over Union(IOU) 이다. SSD에서는 이 값이 일정 값(threshold, 본 논문에서는 0.5)를 넘기기만 하면 일단 일치한다고 가정한다.
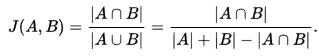
다른 detector들의 구조에서는 IOU가 가장 큰 상자만을 사용하는 경우가 많은 데, 굳이 threshold를 넘는 상자를 모두 선택하는 이유는 높은 정확도를 가진 상자를 한꺼번에 여러번 학습시킴으로써 하나만 고르는 것보다 높은 학습율을 얻기 위해서 이다.
2) Training objective
N: 검출된 박스의 개수 ( N=0 일 시에 loss를 0으로 설정함)
g: ground truth box, 실제 박스의 변수들을 의미한다.
d: default box, default box
c: category, 말 그대로 카테고리
l: predicted boxes, 예상된 박스의 변수들을 의미한다.
cx, cy: offset of center
w,h : width and height
alpha: weight term, 이 값은 교차 검증에 의해 1로 정해졌다고 한다.
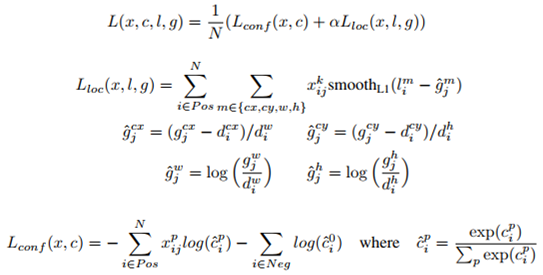
SSD는 역시 deep neural network 이기에, 다른 네크워크와 마찬가지로 loss를 줄이는 방향으로 학습을 한다.
위치와 카테고리를 예상하는 네트워크이기에, loss 역시 그 두 개를 동시에 고려하여야 한다. 가장 위의 식은 전체 loss를 의미하며, 이 값은 위치에 따른 loss (L_loc)과 카테고리 점수에 따른 loss(L_conf) 를 합친 것이다.
3) Scale & Aspect ratios for default boxes
s_min 은 0.2, s_max 는 0.9이며
m 은 multi-feature maps 의 개수이다.
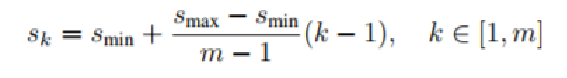
위의 식을 통해, 각 feature map에서 default box의 크기가 얼마나 되는 지를 구한다.
box의 크기를 구했다면, 남은 것은 aspect ratio를 구하는 것이다.
이 예시는 박스가 6개일 때의 예시이다.
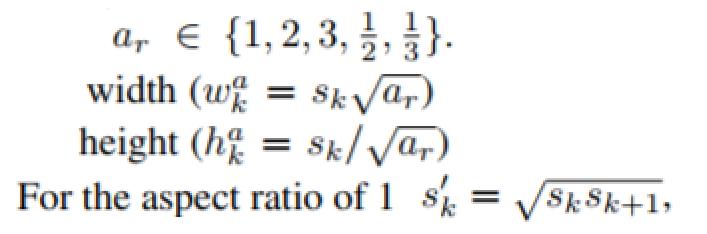
처음에 주어진 숫자가 1, 2 , 1/2 , 3, 1/3 이기에, 각각을 scale과 연상하여 구한 5개의 box와, aspect ratio 가 1일때에는 scale 하나를 더 구해서 1개의 추가적인 box, 즉 6개의 default box가 있는 것이다.
만약 1, 3, 1/3 만을 aspect ratio로 이용한다면 6개가 아닌 4개의 default box가 있게 된다.
4) Hard negative mining
matching을 돌리고 나면 positive에 비해 너무나도 많은 negative sample이 나오게 된다. 이 sample을 모두 훈련시키면, sample을 불균형으로 제대로 학습이 되지 않는다고 한다. 따라서 모든 mathcing 상자들 중, 점수가 상대적으로 높은 것들을 negative로 학습시킨다. 논문의 저자는 negative의 개수를 최대 postive의 3배 까지만 학습을 시키는 것이 최적화가 빨라지고 훈련이 좀 더 안정화된다고 주장한다.
5) Data augmentation
입력을 전부 날 것으로 넣으면, 물체나 환경 변화에 대처를 잘 못하게 된다. 따라서 입력 이미지를 다음 세 개 중에 랜덤으로 선택해서 집어넣어, 좀 더 Robust 하게 훈련을 시킨다.
- 입력 이미지를 그대로 넣기
- 최소 Jaccard overlap이 0.1, 0.3, 0.5, 0.7, 0.9 인 샘플 패치를 넣기
- 랜덤으로 정해진 패치를 넣기
sample들의 size는 원본 사이즈, 혹은 그의 0.1 중에 선택되며 aspect ratio 는 1/2 과 2 사이로 결정된다. 또 이 sample 들은 입력 사이즈에 맞춰진 다음, 50%의 확률로 위 아래가 뒤집혀 질 수도 있다.
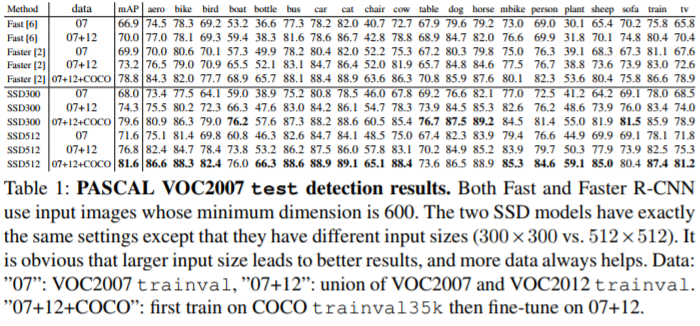
결과
입력 이미지가 커질수록 해상도가 높아지고,검출 할 수 있는 한도가 늘어나 수치가 더 좋게 나온다. SSD300과 SSD512 의 차이는 그 결과이다.
논문의 result 부분을 자세히 살펴보면 training 때에 했던 기술들이 어느정도 성능 향상을 보여주는 것을 확인할 수 있다. 확인해보면 도움이 될 것이다.
마치며
YOLO를 제외한 대부분의 detector들은 Faster R-CNN과 같은 과정을 가지기 때문에, 기존의 detection 방식과 많은 차이가 있음에도 불구하고 속도는 우월하고, 성능도 최신의 것 이상 뽑을 수 있는 구조를 보여주었다는 점은 의미가 크다.
SSD가 만능이라는 것은 아니다. 벌써 YOLO의 새 버전인 YOLO9000은 SSD의 속도와 성능을 모두 따라잡았다. 하지만 SSD는 다른 어떠한 detection network이던 single-shot learning에 이용할 수 있음을 보여주었기에, 이를 알고 있다면 real-time detector 연구에 큰 도움이 될 것이라고 생각한다.
댓글남기기